中國科學院信息工程研究所第六研究室15篇論文被AAAI2025錄用
中國科學院信息工程研究所第六研究室15篇論文被AAAI2025錄用
AAAI 2025(AAAI Conference on Artificial Intelligence) 于12月10日公布了論文接收結果。中國科學院信息工程研究所第六研究室有15篇論文被AAAI2025錄用。
AAAI由國際先進人工智能協會主辦,是人工智能領域的頂級會議之一,也是中國計算機學會(CCF)推薦的A類國際學術會議。AAAI2025共收到12,957篇投稿,其中3,032篇被接受,接受率為23.4%,計劃于2025年02月25日-03月04日在美國費城召開。
下面是錄用論文列表及介紹:
題目:
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
論文作者:
劉曦雨,劉正宵,顧佴彬,林政,馬萬里,向繼,王偉平
論文概述:
知識編輯的目標是修正大語言模型中的錯誤或過時的特定事實,通過調整模型參數來更新其內在知識。近年來,研究者開發了針對Transformer模型中事實存儲和召回機制的方法,能夠在定位到相關參數后進行精準編輯,這類方法已成為主流。然而,現有的編輯方法多依賴于以主實體為中心的知識召回,忽略了關系信息,導致“過度泛化”——即編輯某個事實后,影響了與該主實體相關的其他無關信息。為此,我們提出了一種新的基于關系的編輯方法RETS,它在編輯時同時考慮主實體和具體關系,從而避免對無關信息的影響。實驗顯示,RETS顯著減少了過度泛化現象,并在其他性能指標上保持競爭力,實現了更加均衡的效果,挑戰了傳統以主實體為中心的編輯方式的主導地位。
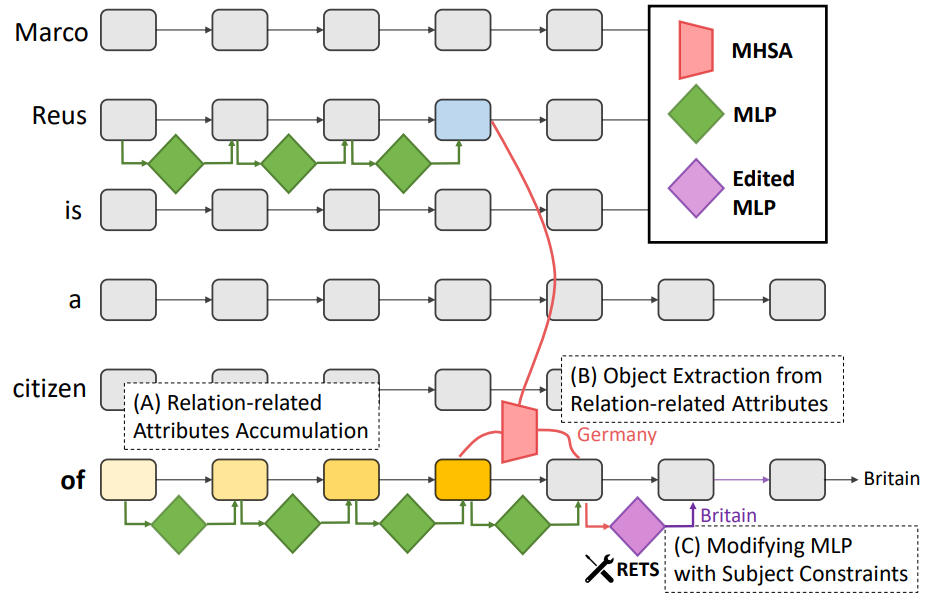
題目:
Trust-GRS: A Trustworthy Training Framework for Graph Neural Network Based Recommender Systems against Shilling Attacks
論文作者:
牟凌宇,劉正宵,朱祉同,林政
論文概述:
基于圖神經網絡(GNN)的推薦系統通過顯式編碼交互行為中的高階鄰居信息,能有效地捕獲用戶興趣和物品特征,因此成為了主流推薦架構之一。最近的研究表明,與傳統推薦架構相比,GNN的鄰域聚合和對比學習機制使其更容易受到先令攻擊的影響。攻擊者通過向推薦系統的訓練集中注入虛假用戶配置文件,從而惡意操控目標物品的排名。盡管已有多種防御方法,但它們通常依賴先驗知識,且難以同時應對多種攻擊類型。基于此,本文提出了一種可信的兩階段GNN推薦系統訓練框架(Trust-GRS),該框架對零知識場景下建模數據偽造的概率,設計出可信的鄰域聚合和對比學習機制。通過在多個基準數據集上針對12種最先進的先令攻擊的廣泛實驗,我們證明了Trust-GRS能夠顯著降低假數據對推薦結果的影響(最高達100%),同時保持原始推薦性能。由于無需依賴先驗知識,Trust-GRS對現實世界的推薦平臺具有重要的應用價值。
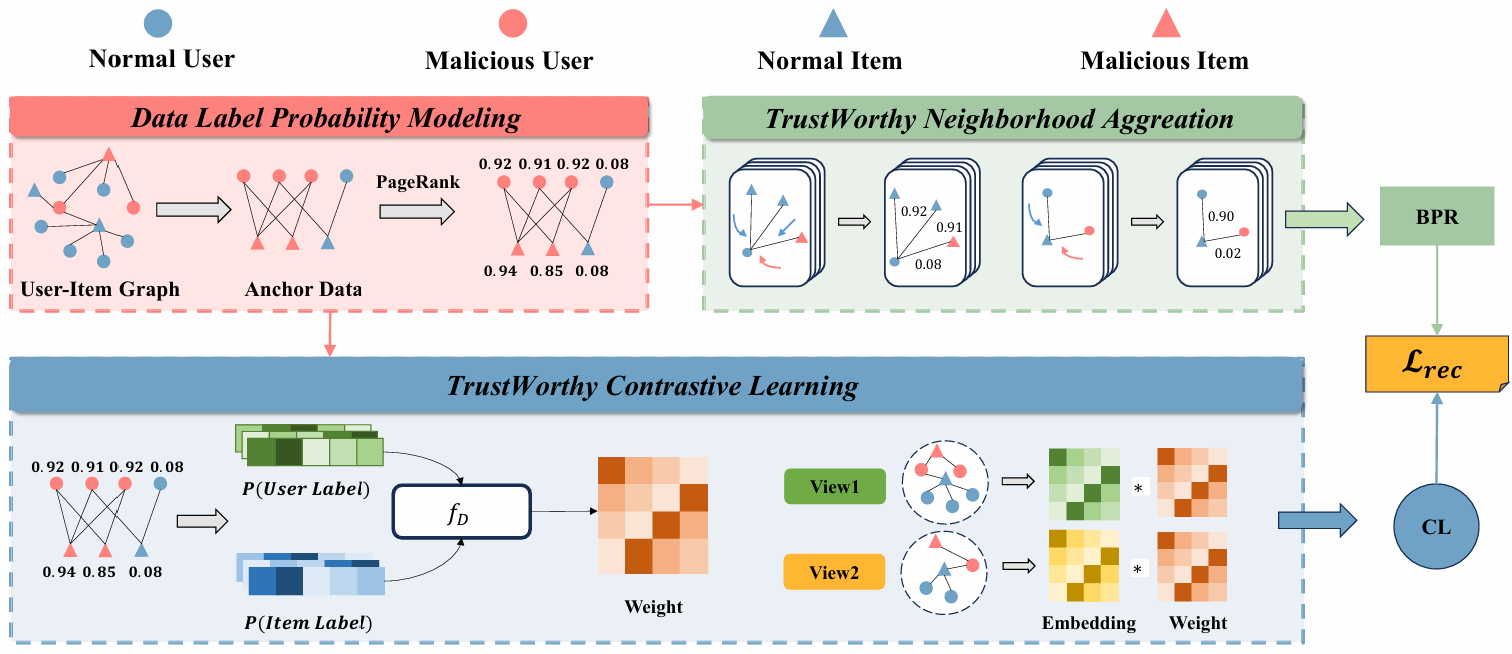
題目:
Multimodal Hypothetical Summary for Retrieval-based Multi-image Question Answering
論文作者:
李佩澤,佀慶一,付鵬,林政,王巖
論文概述:
基于檢索的多圖像問答任務涉及檢索多個與問題相關的圖像并根據這些圖像以生成答案。常規的“先檢索后回答”流程經常遭受級聯錯誤,因為問答的訓練目標未能優化檢索階段。為了解決這個問題,我們提出了一種新穎的方法,有效地將檢索到的信息引入并引用到問答中。給定要檢索的圖像集,我們采用多模態大語言模型(視覺視角)和大語言模型(文本視角)來獲得問題形式和描述形式的多模態假設綜合(MHyS)。通過結合視覺和文本視角,MHyS 更具體地捕獲圖像內容并在檢索中替換真實圖像,轉化為文本到文本的檢索消除了模態差距并有助于改進檢索。為了更好地將檢索與問答結合使用,我們采用對比學習將查詢(問題)與 MHyS 對齊。此外,我們提出了一種從粗到細的策略來計算句子級和單詞級的相似度得分,以進一步增強檢索并過濾掉不相關的細節。我們的方法在 RETVQA 上比最先進的方法實現了3.7%的提升,比CLIP 實現了14.5% 的改進。
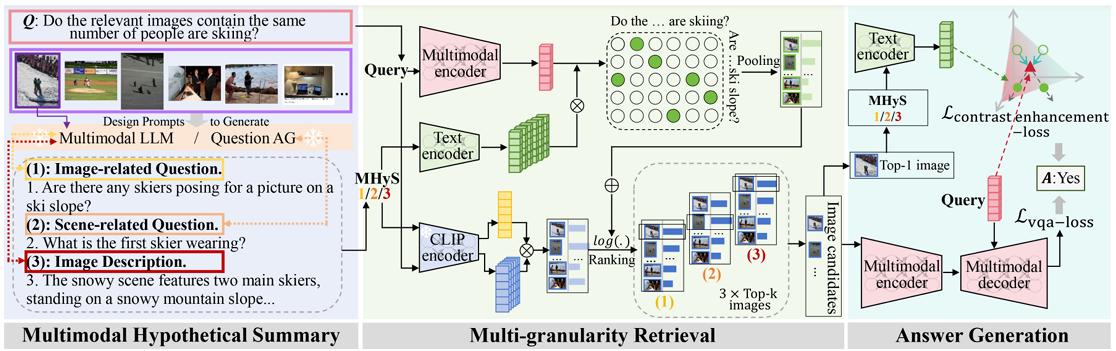
題目:
Union Is Strength! Unite the Power of LLMs and MLLMs for Chart Question Answering
論文作者:
劉佳朋,李亮,饒詩浩,高璽艷,關維鑫,李冰,馬燦
論文概述:
圖表問答(CQA)要求模型具備圖表感知和推理能力。近期,在大型語言模型(LLMs)推動下的相關研究在圖表問答領域占據了主導地位,包括利用認知能力更強的LLM對經過轉換的圖表(即表格)進行間接推理,以及利用感知范圍更廣的多模態大型語言模型(MLLMs)直接對圖表進行感知。然而,圖表到表格的轉化存在信息的損失,限制了LLMs的認知能力;同時部分MLLMs在面臨圖表上的復雜推理時存在推理鏈斷裂的可能。基于此,本文提出新的圖表問答推理框架(Synergy),該框架將圖表問答任務拆解為多個階段,利用不同的信號在各個階段中發揮LLMs和MLLMs的優勢并規避它們的不足。實驗顯示,Synergy顯著提升了單一大模型在圖表問答任務上的表現,并展示出良好的靈活性,即使為MLLMs配備較小的LLMs,仍實現了相對于原始MLLMs直觀性能提升。
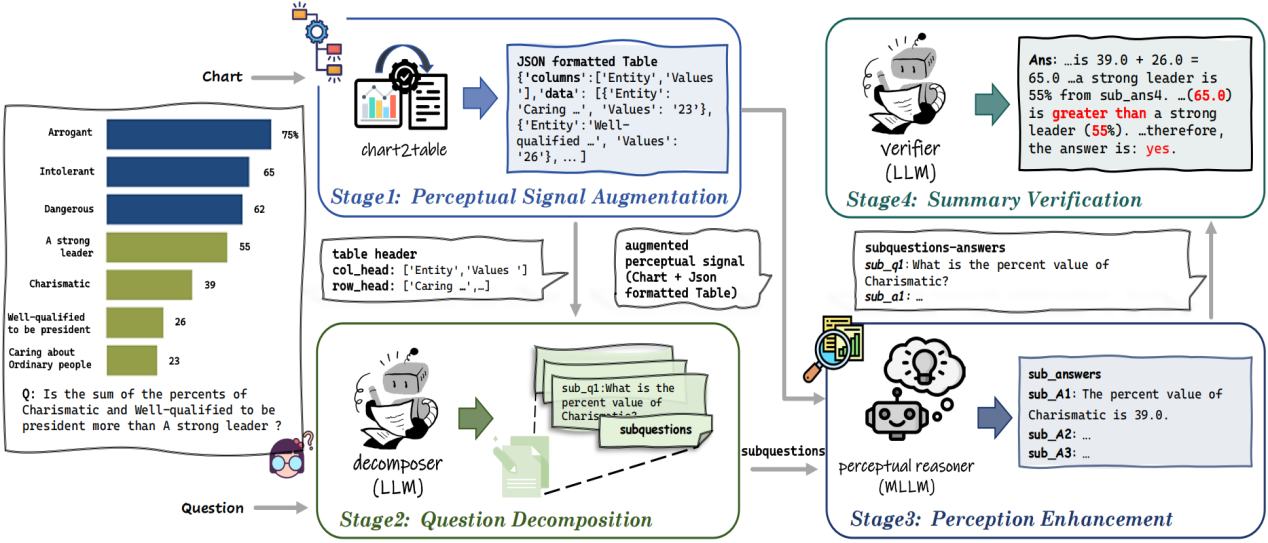
題目:
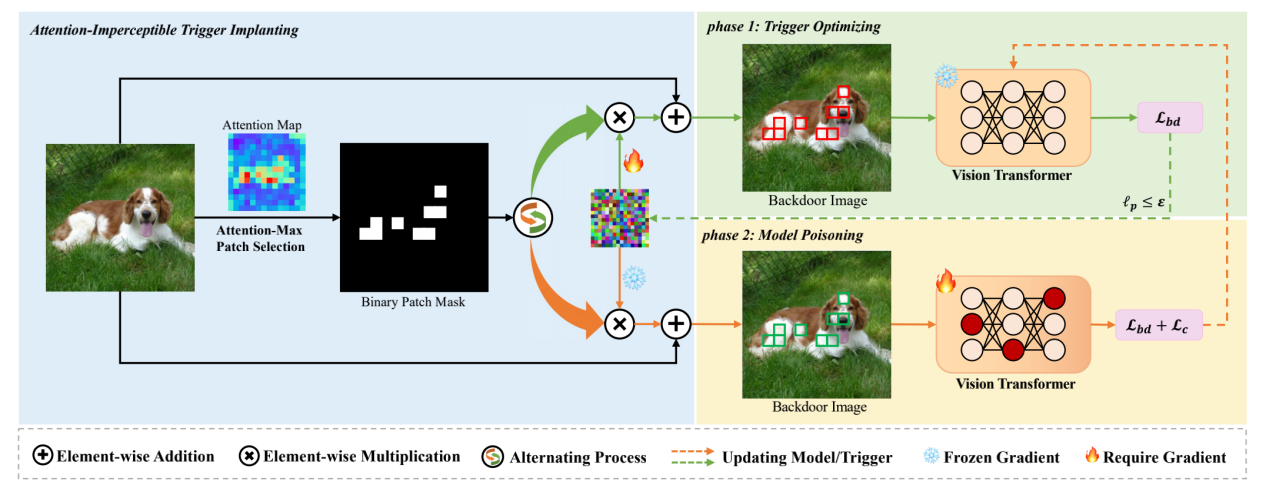
Attention-Imperceptible Backdoor Attacks on Vision Transformers
論文作者:
王植棽,王蕊,荊麗樺
論文概述:
隨著Transformers成功從自然語言處理(NLP)領域過渡到計算機視覺(CV)領域,視覺Transformers(ViTs)在許多計算機視覺任務中取得了最先進的表現。然而,后門攻擊作為深度學習中的一個重要威脅,也對ViT模型的安全性構成了風險。最近,已經提出了幾種針對ViT中補丁級別自注意力機制的后門攻擊方法,但這些方法在隱蔽性和對防御措施的魯棒性方面相對較為簡單,缺乏深入的研究。在本文中,我們探討了注意力級別隱蔽性在ViT后門攻擊中的關鍵作用,并提出了一種新的視覺Transformers注意力隱蔽后門攻擊方法(AIBA)。在AIBA中,采用受限的對抗擾動作為觸發器,以實現視覺隱蔽性。此外,觸發器被設計為無縫地植入到圖像的焦點區域,確保觸發器能得到模型足夠的關注而不在注意力層級上引起異常。在后門學習過程中,我們設計了一種高效的受限雙層優化訓練策略,利用隱蔽觸發器將有效的后門植入受害模型。我們在多個數據集和ViT基準上評估了AIBA方法的有效性,并探討了AIBA對當前ViT特定防御方法的魯棒性。實驗結果表明,我們的后門攻擊方法能夠成功地將強大且隱蔽的后門植入ViT模型。
題目:
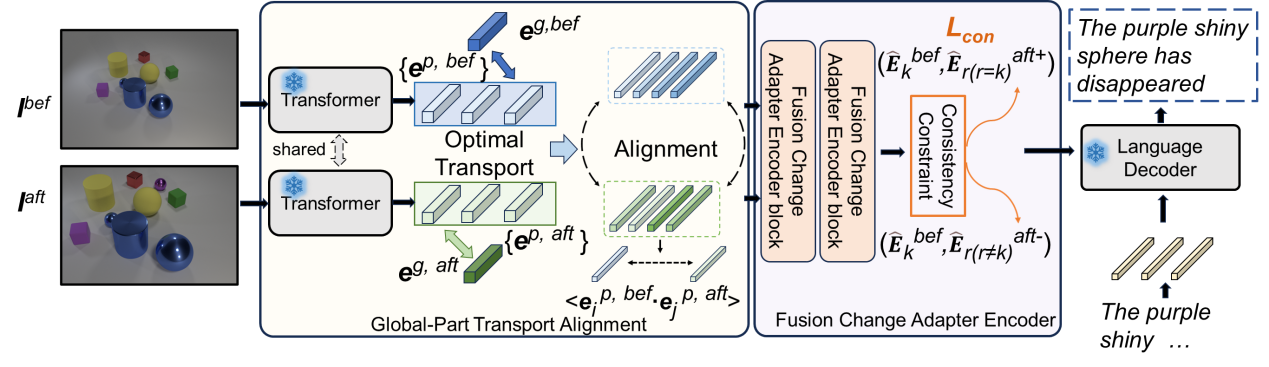
Revisiting Change Captioning from Self-supervised Global-Part Alignment
論文作者:
呂飛霄,王蕊,荊麗樺
論文概述:
圖像變化描述的目標是捕捉兩幅圖像之間的內容差異,并用自然語言進行描述,其中的關鍵是如何從視角變化和圖像整體結構等不穩定的偽變化中識別到穩定的內容變化。盡管現有許多方法將研究目標放在視角變化上,然而該類研究大都是基于簡單的匹配或者針對微小的視角變化,對于視角變化帶來的偽變化(例如物體的近大遠小形變等)效果較差,從而使得對真實變化特征的識別不穩定。基于此,本論文提出了一種自監督的全局-部分對齊(SSGPA)方法,通過增強圖像全局特征的構建過程來重新審視圖像變化描述任務,使模型能夠將視點等全局變化整合到局部變化中,通過對齊成對圖像中的相應部位進一步判定變化區域,并引入適配器和相匹配的一致性損失對偽變化和真實變化進行了針對性的訓練約束,最終生成包含真實變化的描述。本論文在多個常用數據集上對所提方法的多個模塊進行了探討,實驗顯示,所提出的SSGPA方法顯著提高了圖像變化描述的性能。
題目:
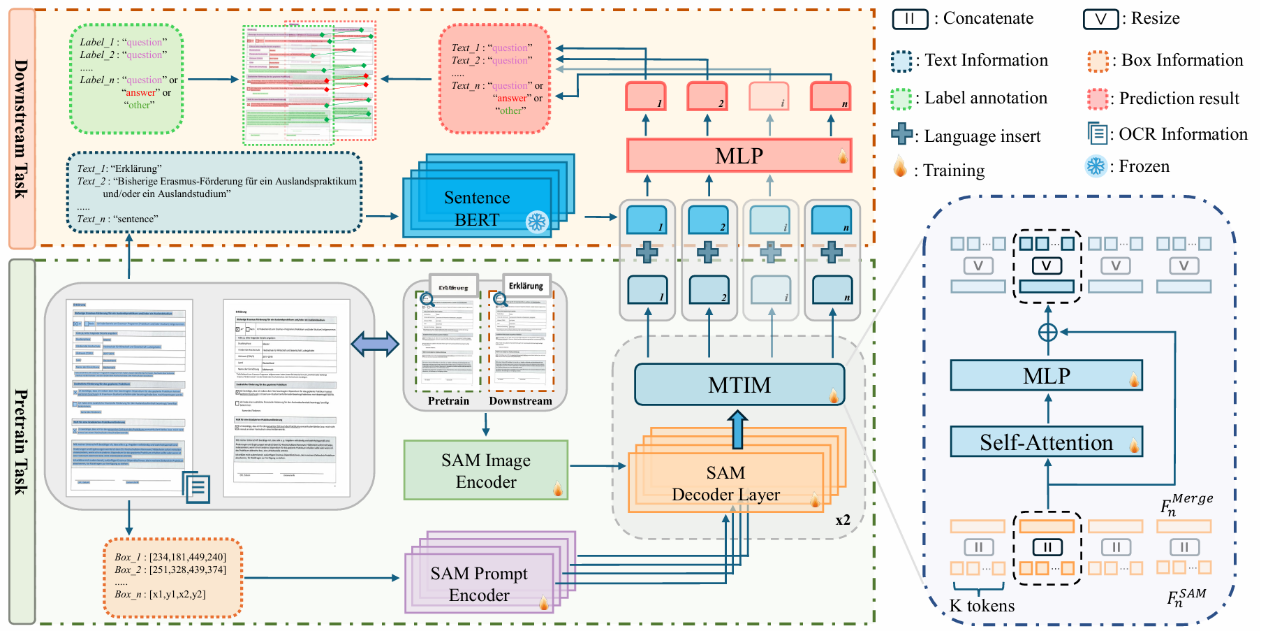
LDP: Generalizing to Multilingual Visual Information Extraction by Language Decoupled Pretraining
論文作者:
申化文,李庚洛,鐘進文,周宇
論文概述:
目前的視覺文檔信息抽取研究大多是單語種的(英語)。本文通過系統性的實驗發現,在不同語言的圖像中,視覺和布局模態具有不變性。如果從文檔圖像中解耦語言偏差,一個基于視覺和布局的模型可以實現優異的跨語言泛化能力。基于此,本文提出了一種簡單但有效的多語言訓練范式 LDP(Language Decoupled Pre-training),基于此訓練的模型LDM(Language Decoupled Model)僅使用英語進行預訓練,在多個語種的下游數據集中都取得了優異的表現。
題目:
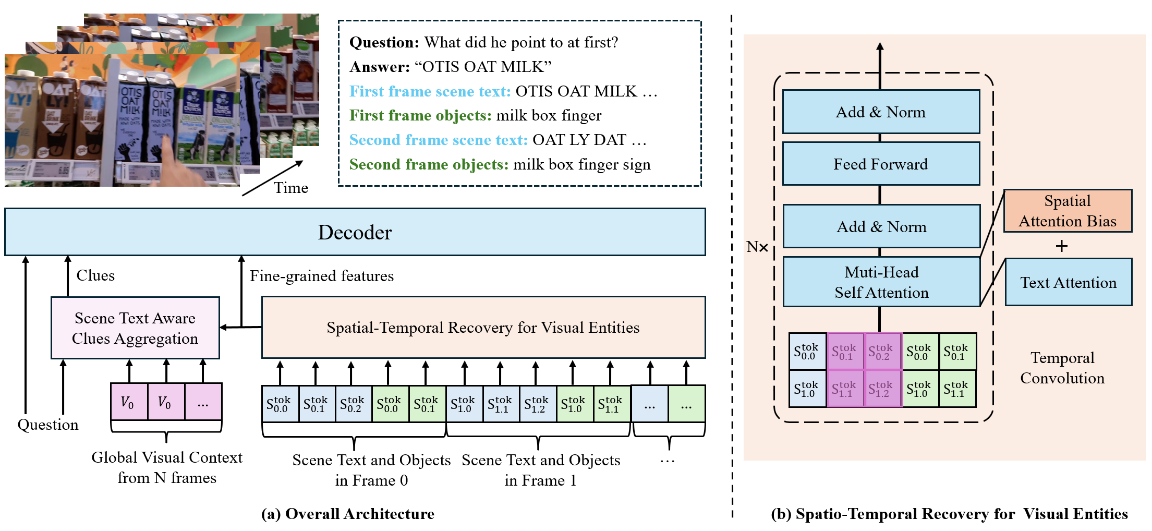
Track the Answer: Extending TextVQA from Image to Video with Spatio-Temporal Clues
論文作者:
張言,曾港艷,申化文,吳岱卿,周宇,馬燦
論文概述:
視頻場景文字視覺問答(Video TextVQA)是一項實用任務,旨在通過聯合推理視頻中的可視文字和視覺對象回答問題。受圖像領域中,場景文字視覺問答(TextVQA)發展的啟發,現有的Video TextVQA方法利用語言模型(如T5)處理包含豐富文本信息的多幀視頻,并以自回歸的方式生成答案。然而,視覺實體(包括場景文字和視覺對象)之間的時空關系容易被破壞,模型也容易受到無關信息的干擾,導致推理不合理和答案不準確。為了解決這些挑戰,我們提出了TEA,進一步將生成式TextVQA框架從圖像擴展到視頻。TEA通過互補的方式恢復了時空關系,并結合了OCR感知的線索,以增強對問題的推理質量。在多個Video TextVQA數據集上的大量實驗,驗證了我們框架的有效性和泛化能力。TEA在性能上遠超現有的TextVQA方法、視頻語言預訓練方法以及視頻大模型。代碼和數據集開源:https://github.com/zhangyan-ucas/TEA。
題目:
Arbitrary Reading Order Scene Text Spotter with Local Semantics Guidance
論文作者:
呂嘉昊,王威,楊東寶,鐘進文,周宇
論文概述:
針對傳統提取范式帶來的閱讀順序缺失問題,本文提出了一個利用局部語義引導面向任意閱讀順序的場景文字提取器,能夠自回歸解碼位置和局部語義指導的字符內容。通過設計了起始點定位和多尺度自適應注意力模塊,在完成任意閱讀順序文字提取任務的基礎上減輕計算開銷。實驗在多個數據集上驗證本方法在任意閱讀順序的場景中有顯著效果。
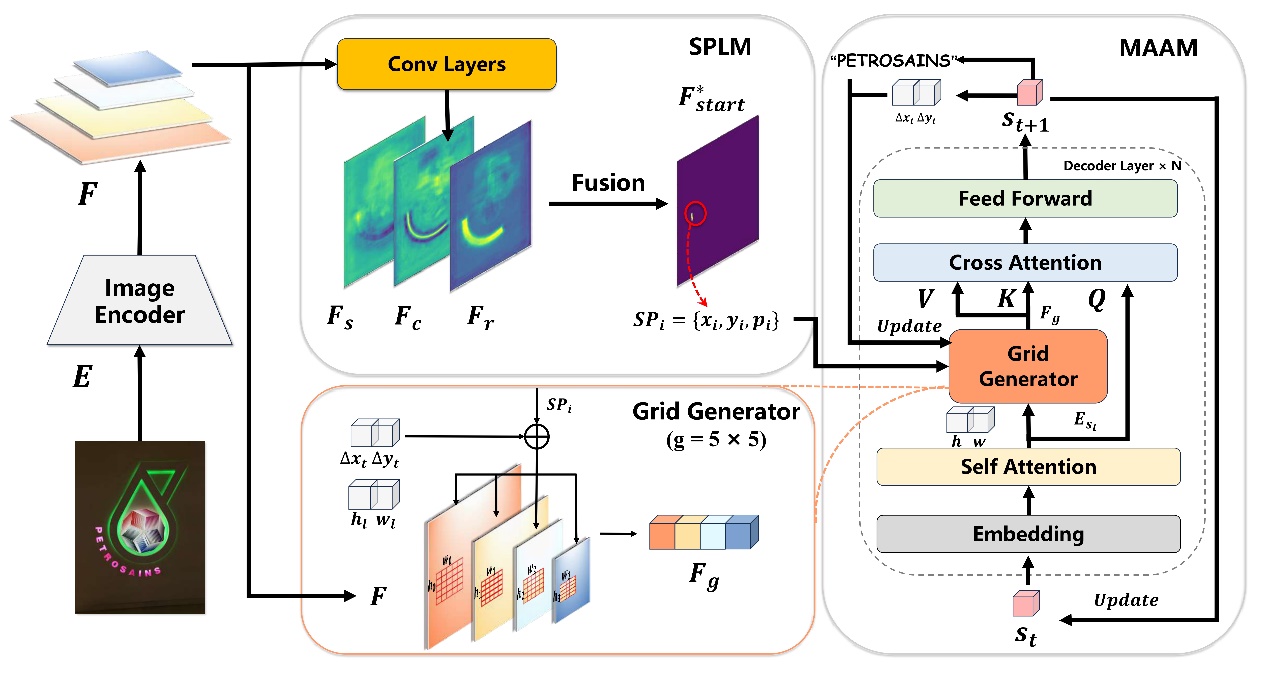
題目:
DCA: Dividing and Conquering Amnesia in Incremental Object Detection
論文作者:
張傲婷,楊東寶,劉暢,洪曉鵬,尚苗,周宇
論文概述:
現有的增量目標檢測(IOD)方法通過改進知識蒸餾和樣例重放取得了一定的成功,但遺忘的內在機制仍未得到充分探索。本文深入研究了其遺忘原因,發現了基于Transformer的增量檢測中定位和識別之間存在遺忘不平衡,并提出一種分治健忘癥策略,將基于Transformer的IOD重新設計為先定位后識別的過程,以保持和遷移定位能力,同時將預訓練語言模型編碼的語義知識有效嵌入在識別解碼過程中,以減少識別特征的漂移。大量實驗驗證了本文方法有效緩解了增量目標檢測中的災難性遺忘,并且具有無需樣例重放的優勢。
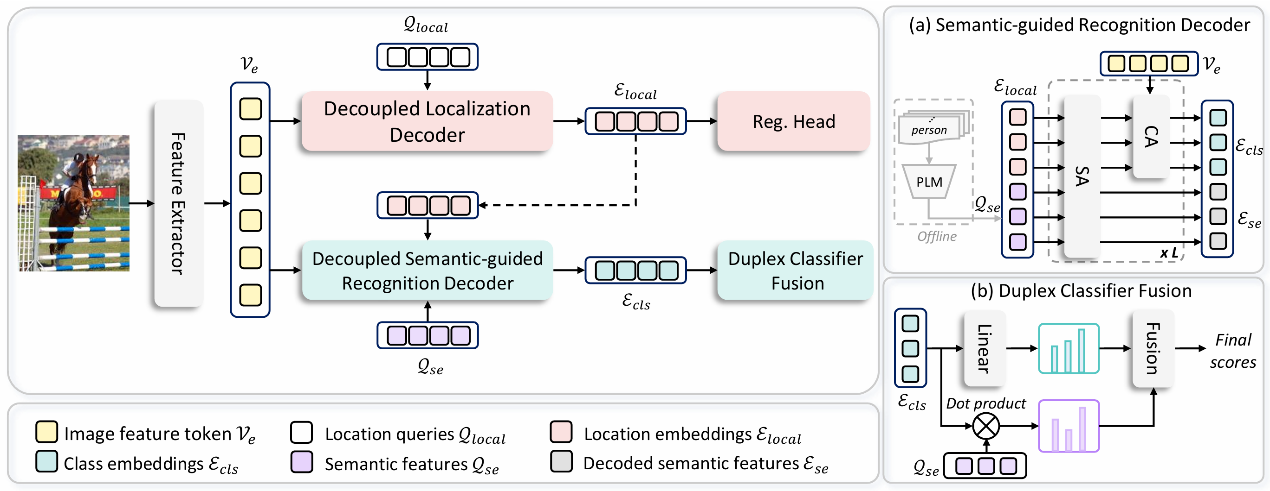
題目:
Specifying What You Know or Not for Multi-Label Class-Incremental Learning
論文作者:
張傲婷,楊東寶,劉暢,洪曉鵬,周宇
論文概述:
針對多標簽類增量學習(MLCIL)中標簽不完整帶來學習目標沖突的問題,本文認為克服這一沖突的主要挑戰在于模型無法明確區分已知和未知知識,這種模糊性阻礙了模型同時保留歷史知識、掌握當前知識和為未來學習做準備的能力。本文旨在明確當前增量會話中已知和未知的知識以同時容納歷史、當前和未來知識,并提出了新框架HCP。HCP首先通過動態特征純化和帶分布先驗的回憶增強來澄清已知知識,從而提高已知信息的精度和保留率。通過設計前瞻性知識挖掘來探索未知領域,為未來的學習預留特征空間。大量實驗驗證了此方法有效地緩解了 MLCIL 中的災難性遺忘。
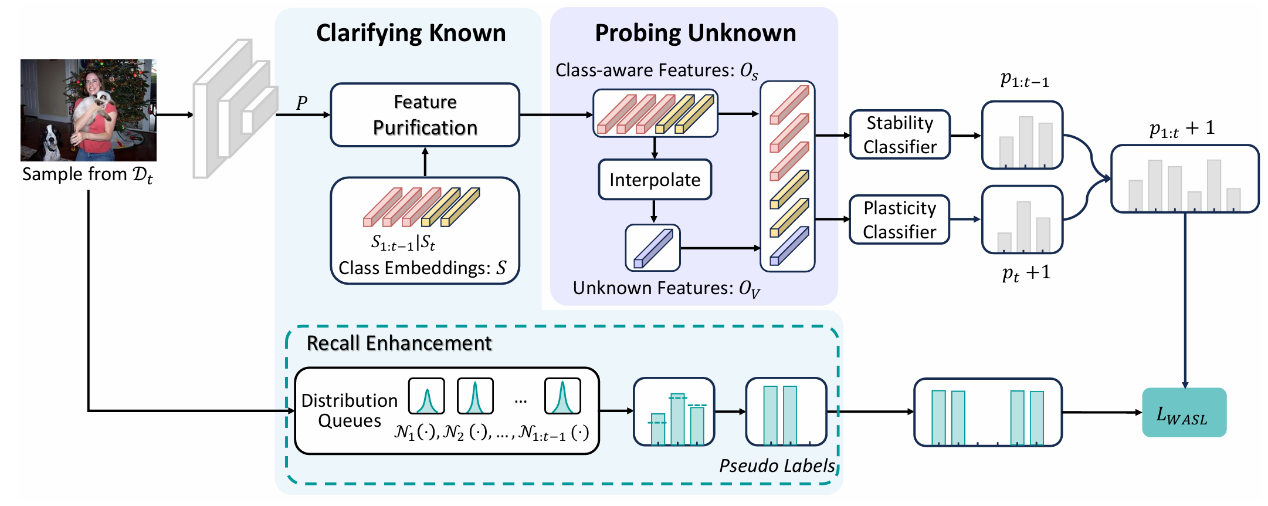
題目:
BotSim: LLM-Powered Malicious Social Botnet Simulation
論文作者:
喬博宇,李鯤,周薇,李世龍,逯倩倩,虎嵩林
論文概述:
Twitter、Reddit等社交媒體對全球交流至關重要,但大語言模型(LLM)技術的飛躍催生了高度智能的社交機器人。這些機器人能夠精準模仿人類行為,散布大量虛假信息,給平臺監管帶來嚴峻挑戰。為應對此威脅,本文創新性地提出BotSim—一個由LLM賦能的惡意社交機器人網絡模擬系統。BotSim模擬真實社交網絡的信息傳播,構建了一個融合智能代理機器人與真實用戶的虛擬環境。在模擬的時間線中,機器人能夠進行自主發帖、評論等互動,還原了真實環境中信息流推薦和用戶交互的場景。基于BotSim框架,本文進一步創建了高度擬人化、由LLM驅動的機器人數據集BotSim-24,并對其進行了一系列機器人檢測策略的基準測試。實驗結果顯示,針對傳統機器人數據集有效的方法在BotSim-24上表現較差,這凸顯了迫切需要新的檢測策略來解決這些先進機器人帶來的網絡安全威脅。
題目:
Task-level Distributionally Robust Optimization for Large Language Model-based Dense Retrieval
論文作者:
馬廣遠,馬永亮,伍星,蘇振鵬,周明,虎嵩林
論文概述:
隨著基礎模型的改進、數據量的增加,以大模型(LLM)為基座的稠密檢索(Dense Retrieval, DR)模型取得了優異的檢索性能。大模型稠密檢索(LLM-DR)基于大量異質的微調數據集進行訓練,這些異質數據集的領域、語言、對稱性等特征差異巨大。如何確定一個合適的數據分布或配比,使得這些數據集聯合訓練的性能達到更優,是提升大模型稠密檢索性能的關鍵;現有研究中,關于大模型稠密檢索的數據分布優化(Data Distributional Optimization)仍處于空白狀態。如何決定使用哪些數據集、如何確定每個數據集使用的比例、以及如何用更少的數據達到更優的性能,常基于研究人員的經驗性判斷,通過反復的實驗來解決這些問題。然而,我們不可能窮盡數據集聯合訓練的所有配比,這種經驗性的試錯空間巨大、代價較高,模型的魯棒性不強,將不可避免地處于次優(Sub-optimal)狀態,影響大模型稠密檢索的性能表現;為了解決上述異質數據集聯合訓練的分布優化問題,我們提出了一種面向大模型稠密檢索的任務級分布魯棒優化(Task-level Distributionally Robust Optimization, tDRO)算法,端到端地學習魯棒的數據分布。在大規模的開源文本檢索訓練集的聯合訓練場景中,本方法減少了30% 的數據集用量;并在大規模的單語、多語、跨語言檢索基準中,顯著提升了不同尺寸(500M, 1.8B, 4B, 7B, 8B)、不同基座(Qwen1.5, LLaMA3, Mistral-0.1)的大模型稠密檢索的性能表現。

題目:
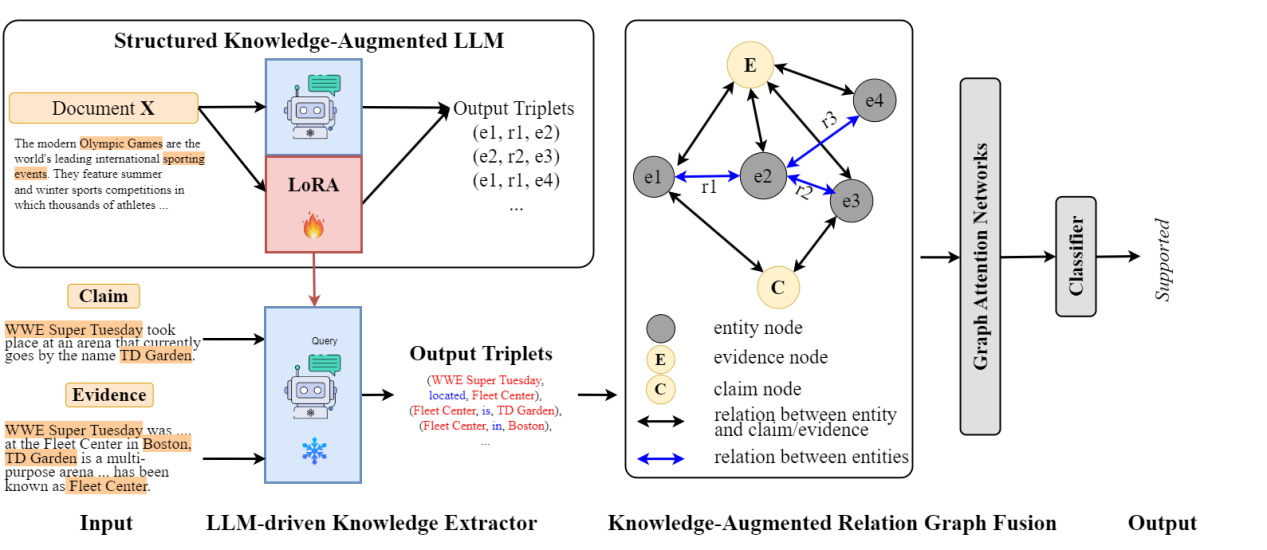
Enhancing Multi- hop Fact Verification with Structured Knowledge-Augmented Large Language Models
論文作者:
曹晗,衛玲蔚,周薇,虎嵩林
論文概述:
社交平臺的迅速發展加劇了虛假、錯誤信息的傳播,這促使了事實核查研究的發展。近期的研究傾向于利用語義特征將此問題作為單跳任務來解決。然而,在現實情況中,驗證一個聲明需要多條證據,這些證據之間存在復雜的內在邏輯和關系。近期的研究試圖通過提高理解和推理能力來提升性能,但它們忽略了實體之間的關鍵關系,而這些關系有助于模型更好地理解并促進預測。為了強調關系的重要性,我們借助大型語言模型(LLMs),因為它們具有出色的理解能力。與將 LLM 用作預測器的其他方法不同,我們將其用作關系抽取器,因為實驗結果表明它們在理解方面表現更佳而非推理。因此,為了解決上述挑戰,我們提出了一種基于 LLM 的結構化知識增強網絡(LLM-SKAN),用于多跳事實核查。具體來說,我們利用一個由大型語言模型驅動的知識提取器來捕獲細粒度的信息,包括實體及其關系。此外,我們借助知識增強的關系圖融合模塊與每個結點進行全面交互,并學習更優的聲明——證據表示。在四個常用數據集上的實驗結果證明了我們模型的有效性。
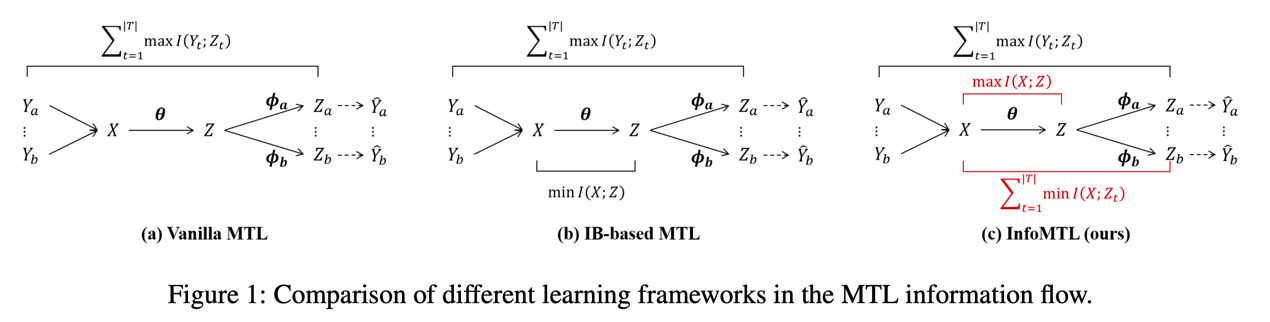
題目:
An Information-theoretic Multi-task Representation Learning Framework for Natural Language Understanding
論文作者:
胡斗,衛玲蔚,周薇,虎嵩林
論文概述:
本文提出了一種基于信息論的多任務表示學習框架(InfoMTL),用于提取噪聲不變的、對所有任務均充分的潛在表示,以增強多任務范式下預訓練語言模型的語言理解能力。該框架引入了兩個學習準則:共享信息最大化 (SIMax) 和任務特定信息最小化 (TIMin)。SIMax 旨在促進共享表示保留所有任務所需的必要信息,而 TIMin 旨在消除每個任務特定的冗余信息。在六個分類基準的實驗表明,InfoMTL 在不同網絡骨架下的多任務表現均一致優于現有的多任務學習方法,且在數據受限和噪聲場景具有顯著優勢。擴展實驗表明,提出方法學習到的表示更加充分、數據高效且魯棒。代碼實現見 https://github.com/zerohd4869/InfoMTL。

 上一篇:生成式人工智能安全技術專項技術短期培訓班暨中國科學院首屆NLPer大會圓滿落幕
上一篇:生成式人工智能安全技術專項技術短期培訓班暨中國科學院首屆NLPer大會圓滿落幕 附件下載 :
附件下載 :